Hello and welcome to #root.bg!
Here you can find tutorials about linux, networks and their firewall, games and fun, as well as hobbies – rollers, drones and many more.
Here you can find tutorials about linux, networks and their firewall, games and fun, as well as hobbies – rollers, drones and many more.
Здравейте,
Днес ми се случи отпадане на един MySQL сървър, и в резултат на това се получи така наречения MariaDB Galera Cluster Split Brain.
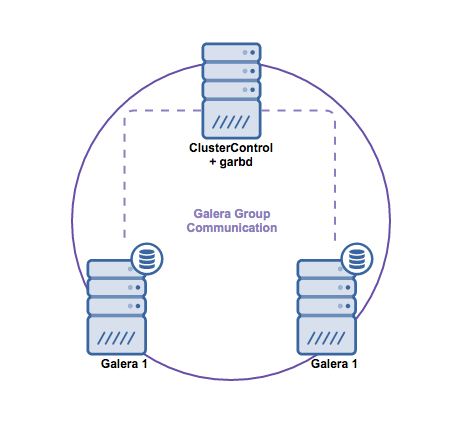
Тъй като използвам 2 нода, което не е препоръчително за Galera Cluster, сутринта работещия нод връщаше следната грешка:
WSREP has not yet prepared node for application use
След като оправих проблемния нод (достатъчен беше един рестарт), реших да се справя и с този Split Brain.
Идеята като цяло беше, да добавя трети нод в клъстера, или да включа арбитър.
mysql> show status like 'wsrep_cluster_size'; +--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | wsrep_cluster_size | 2 | +--------------------+-------+ 1 row in set (0.01 sec)
За да увелича размера на клъстера до 3, инсталирах и конфигурирах galera arbitrator на трета машина с минимални ресурси.
apt-get install galera-arbitrator-3
Тъй като клъстера ми използва SSL сертификати, се наложи да ги копирам и на тази машина, за да мога да стартирам garbd демона.
Конфигурационният му файл (/etc/default/garb) изглежда така :
# Copyright (C) 2012 Codership Oy # This config file is to be sourced by garb service script. # A comma-separated list of node addresses (address[:port]) in the cluster GALERA_NODES="192.168.168.1:4567 192.168.168.16:4567" # Galera cluster name, should be the same as on the rest of the nodes. GALERA_GROUP="cbz_cluster" # Optional Galera internal options string (e.g. SSL settings) # see http://galeracluster.com/documentation-webpages/galeraparameters.html GALERA_OPTIONS="socket.ssl_key=/etc/mysql/ssl/server-key.pem;socket.ssl_cert=/etc/mysql/ssl/server-cert.pem;socket.ssl_ca=/etc/mysql/ssl/ca-cert.pem;socket.ssl_cipher=AES128-SHA" # Log file for garbd. Optional, by default logs to syslog # LOG_FILE="/var/log/garbd.log"
Последна стъпка – стартиране на процеса :
web-root:~# /etc/init.d/garb restart . ok [ ok ] Starting /usr/bin/garbd: :.
И wsrep_cluster_size вече беше 3.
mysql> show status like 'wsrep_cluster_size'; +--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | wsrep_cluster_size | 3 | +--------------------+-------+ 1 row in set (0.00 sec)
Така при отпадане на един от нодовете, другия ще продължи да работи нормално.
Това е!
 Привет,
Привет,
Както сигурно е ясно на всички, аз не съм от най-големите фенове на exim, но заради работата с WHM, се налага да го поназнайвам от време на време.
Днес ще споделя за проблем, който се случи на няколко мейл акаунта на наш сървър с WHM и exim.
Проблемът беше, че изпращането и получаването на мейли не функционираше коректно, и даваше грешка :
(Verification failed for <testtest@builders-domain.co.uk> The mail server could not deliver mail to testtest@builders-domain.co.uk. The account or domain may not exist, they may be blacklisted, or missing the proper dns entries. Sender verify failed).
По пътя на логиката тръгнах да проверявам :
И тук дойде момента да направя така наречения Exim debug.
Командата която използвах и ми помогна за разрешаването на проблема беше следната :
exim -d -bt testtest@builders-domain.co.uk
И резултата беше следния :
local_part=marketing domain=builders-domain.co.uk checking domains search_open: lsearch "/etc/localdomains" search_find: file="/etc/localdomains" key="builders-domain.co.uk" partial=-1 affix=NULL starflags=0 LRU list: 5/etc/localdomains End internal_search_find: file="/etc/localdomains" type=lsearch key="builders-domain.co.uk" file lookup required for builders-domain.co.uk in /etc/localdomains lookup failed builders-domain.co.uk in "lsearch;/etc/localdomains"? no (end of list) builders-domain.co.uk in "+local_domains"? no (end of list) deliver_local_outside_jail router skipped: domains mismatch
Тоест проблема беше изключително глупав : домейна не присъстваше в /etc/localdomains и заради това изпращането и получаването към него не функционираше. Явно това е бъг в трансферирането на акаунти от WHM към WHM, но чрез тези команди на exim успях да го открия.
Ами.. това е!
Привет,
Днес сутринта след рутинен update на пакетите на DB сървърите попаднах на MySQL Galera cluster crash.
За няколко минути cluster-а ми се счупи тотално и част от апликациите на root.bg не работиха.

Ето как започна всичко :
След
apt-get update && apt-get upgrade -y
нещата се объркаха :
Setting up mariadb-server-10.1 (10.1.22+maria-1~xenial) ... Job for mariadb.service failed because the control process exited with error code. See "systemctl status mariadb.service" and "journalctl -xe" for details. invoke-rc.d: initscript mysql, action "start" failed. ● mariadb.service - MariaDB database server Loaded: loaded (/lib/systemd/system/mariadb.service; enabled; vendor preset: enabled) Drop-In: /etc/systemd/system/mariadb.service.d └─migrated-from-my.cnf-settings.conf Active: failed (Result: exit-code) since Thu 2017-03-16 10:35:22 EET; 4ms ago Process: 13607 ExecStartPre=/bin/sh -c [ ! -e /usr/bin/galera_recovery ] && VAR= || VAR=`/usr/bin/galera_recovery`; [ $? -eq 0 ] && systemctl set-environment _WSREP_START_POSITION=$VAR || exit 1 (code=exited, status=1/FAILURE) Process: 13602 ExecStartPre=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS) Process: 13597 ExecStartPre=/usr/bin/install -m 755 -o mysql -g root -d /var/run/mysqld (code=exited, status=0/SUCCESS) Main PID: 19373 (code=exited, status=0/SUCCESS) Mar 16 10:35:22 border mysqld[13607]: Segmentation fault (core dumped)
Веднага предприех опит да възтановя базите чрез вградения скрипт на galera за recovery :
galera_recovery
обаче резултата не беше такъв какъвто се надявах да бъде :
 Привет,
Привет,
От известно време в един proxmox cluster ми се случва следното – при рестартиране на MySQL сървър работещ като slave, репликацията спира да работи, и връща грешка : MySQL error 1594.
Положението изглежда долу-горе така :
Slave_IO_State: Waiting for master to send event Master_Host: 192.168.188.223 Master_User: replicator Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.002046 Read_Master_Log_Pos: 70104169 Relay_Log_File: mysql-relay-bin.001957 Relay_Log_Pos: 243 Relay_Master_Log_File: mysql-bin.004319 Slave_IO_Running: Yes Slave_SQL_Running: No Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 1594 Last_Error: Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's binary log is corrupted (you can check this by running 'mysqlbinlog' on the binary log), the slave's relay log is corrupted (you can check this by running 'mysqlbinlog' on the relay log), a network problem, or a bug in the master's or slave's MySQL code. If you want to check the master's binary log or slave's relay log, you will be able to know their names by issuing 'SHOW SLAVE STATUS' on this slave. Skip_Counter: 0 Exec_Master_Log_Pos: 70104169 Relay_Log_Space: 983411603 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 1594
До сега решавах проблема, като dump-вах базата от мастър сървъра и я наливах на ново със съответните master_log_file позиция и master_log_pos. Базата ни обаче стана прекалено голяма, и подобен dump започна да отнема много време. За това се наложи да намерим алтернативен начин за разрешаване на този проблем.
За целта е нужна следната информация от:
show slave status \G;
Exec_Master_Log_Pos: 70104169 Relay_Master_Log_File: mysql-bin.004319
Напрактика това са последните актуални данни от мастър сървъра ни, преди слейва ни да спре да репликира.
За да оправим проблема пишем следното на слейв-а :
stop slave; reset slave; change master to master_log_file='mysql-bin.004319', master_log_pos= 70104169; start slave;
И благодарение на mytop можем да наблюдаваме в реално време как върви синхронизацията на MySQL сървъра ни. След като се настигне с мастър-а вече всичко трябва да е ок!
Това е! 🙂